
Abstract
Seed dispersal is a critical mechanism for escaping specialist natural enemies. Despite this, mean dispersal distances can vary by an order of magnitude among plant species in the same community. Here, we develop a theoretical model to explore how interspecific differences in seed dispersal alter the impact of specialist natural enemies, both on their own and though a trade-off between seed dispersal and enemy susceptibility. Our model suggests that species are more able to recover from rarity if they have high dispersal because (1) seedlings are more likely to escape their parent’s natural enemies, (2) adults are more spread out, reducing the chance that a seed will disperse near conspecifics, and (3) seedlings compete less with kin for open gaps. Differences in dispersal do not produce stabilizing mechanisms—species with low dispersal are purely at a disadvantage and do not gain a novel niche opportunity. However, dispersal-susceptibility trade-offs will be equalizing, as species disadvantaged by low dispersal will benefit from being less susceptible to specialist natural enemies. This mechanism, unlike most mechanisms of dispersal-mediated coexistence, does not require that there is an abundance of empty space: high-dispersers gain an advantage by escaping from their enemies, not by colonizing empty habitat. Our study therefore suggests that differences in dispersal are unlikely to promote diversity on their own, but may strengthen other coexistence mechanisms.






Similar content being viewed by others

References
Adler FR, Muller-Landau HC (2005) When do localized natural enemies increase species richness? Ecol Lett 8(4):438–447
Augspurger CK (1983) Seed dispersal of the tropical tree, Platypodium elegans, and the esape of its seedlings from fungal pathogens. J Ecol 71(3):759–771
Augspurger CK, Kelly CK (1984) Pathogen mortality of tropical tree seedlings - experimental studies of the effects of dispersal distance, seedling denisity, and light conditions. Oecologia 61(2):211–217
Barabás G, D’Andrea R, Stump SM (2018) Chesson’s coexistence theory. Ecol Monogr 88(3):277–303
Becker P, Wong M (1985) Seed dispersal, seed predation, and juvenile mortality of Aglaia sp (Meliaceae) in lowland dipterocarp rainforest. Biotropica 17(3):230–237
Beckman NG, Bullock JM, Salguero-Gȯmez R (2018) High dispersal ability is related to fast life-history strategies. J Ecol 106(4):1349–1362
Bever JD (1994) Feedback between plants and their soil communities in an old field community. Ecology 75(7):1965–1977
Bever JD, Westover KM, Antonovics J (1997) Incorporating the soil community into plant population dynamics: the utility of the feedback approach. J Ecol 85(5):561–573
Bolker BM, Pacala S (1999) Spatial moment equations for plant competition: understading spatial strategies and the advantages of short dispersal. Am Nat 153(6):575–602
Bullock JM, Mallada González L, Tamme R, Gȯtzenberger L, White SM, Pȧrtel M, Hooftman DA (2017) A synthesis of empirical plant dispersal kernels. J Ecol 105(1):6–19
Chen Y, Jia P, Cadotte MW, Wang P, Liu X, Qi Y, Jiang X, Wang Z, Shu W (2019) Rare and phylogenetically distinct plant species exhibit less diverse root-associated pathogen communities. J Ecol 107(3):1226–1237
Chesson P (1994) Multispecies competition in variable environments. Theor Popul Biol 45 (3):227–276
Chesson P (2000) General theory of competitive coexistence in spatially-varying environments. Theor Popul Biol 58(3):211–237
Chesson P (2003) Quantifying and testing coexistence mechanisms arising from recruitment fluctuations. Theor Popul Biol 64(3):345–357
Chisholm RA, Muller-Landau HC (2011) A theoretical model linking interspecific variation in density dependence to species abundances. Theor Ecol 4(2):241–253
Clark AT, Detto M, Muller-Landau HC, Schnitzer SA, Wright SJ, Condit R, Hubbell SP (2018) Functional traits of tropical trees and lianas explain spatial structure across multiple scales. J Ecol 106 (2):795–806
Clark JS, Silman M, Kern R, Macklin E, HilleRisLambers J (1999) Seed dispersal near and far: patterns across temperate and tropical forests. Ecology 80(5):1475–1494
Cobo-Quinche J, Endara MJ, Valencia R, Muṅoz-Upegui D, Cȧrdenas R E (2019) Physical, but not chemical, antiherbivore defense expression is related to the clustered spatial distribution of tropical trees in an Amazonian forest. Ecol Evol 9(4):1750–1763
Comita LS, Aguilar S, Pėrez R, Lao S, Hubbell SP (2007) Patterns of woody plant species abundance and diversity in the seedling layer of a tropical forest. J Veg Sci 18:163–174
Comita LS, Muller-Landau HC, Aguilar S, Hubbell SP (2010) Asymmetric density dependence shapes species abundances in a tropical tree community. Science 329(5989):330–332
Comita LS, Queenborough SA, Murphy SJ, Eck JL, Xu K, Krishnadas M, Beckman N, Zhu Y (2014) Testing predictions of the Janzen–Connell hypothesis: a meta-analysis of experimental evidence for distance- and density-dependent seed and seedling survival. J Ecol 102(4):845–856
Condit R, Ashton PS, Baker PJ, Bunyavejchewin S, Guantilleke S, Guantilleke N, Hubbell SP, Foster RB, Itoh A, Lafrankie JV, Lee HS, Losos E, Manokaran N, Sukumar R, Yamakura T (2000) Spatial patterns in the distribution of tropical tree species. Science 288(5470):1414–1418
Connell JH (1971) On the role of natural enemies in preventing competitive exclusion in some marine animals and rainforest trees. In: Gradwell PJdb G (ed) Dynamics of populations, Centre for Agricultural Publishing and Documentation, Wageningen, pp 298–312
Detto M, Muller-Landau HC (2016) Rates of formation and dissipation of clumping reveal lagged responses in tropical tree populations. Ecology 97(5):1170–1181
Durrett R, Levin S (1994) The importance of being discrete (and spatial). Theor Popul Biol 46(3):363–394
Ellner SP, Snyder RE, Adler PB (2016) How to quantify the temporal storage effect using simulations instead of math. Ecol Lett 19(11):1333–1342
Ellner SP, Snyder RE, Adler PB, Hooker G (2019) An expanded modern coexistence theory for empirical applications. Ecol Lett 22(1):3–18
Freckleton RP, Lewis OT (2006) Pathogens, density dependence and the coexistence of tropical trees. Proc R Soc B-Biol Sci 273(1604):2909–2916
Fricke EC, Wright SJ (2017) Measuring the demographic impact of conspecific negative density dependence. Oecologia 184(1):259–266
Fricke EC, Tewksbury JJ, Rogers HS (2014) Multiple natural enemies cause distance-dependent mortality at the seed-to-seedling transition. Ecol Lett 17(5):593–598
Gillett JB (1962) Pest pressure, an underestimated factor in evolution. In: Taxonomy and geography; a symposium, vol 4, pp 37–46
Gross K (2008) Fusing spatial resource heterogeneity with a competition–colonization trade-off in model communities. Theor Ecol 1(2):65–75
Grover JP (1994) Assembly rules for communities of nutrient-limited plants and specialist herbivores. Am Nat 143(2):258–282
Hastings A (1980) Disturbance, coexistence, history, and competition for space. Theor Popul Biol 18(3):363–373
Hastings A (1983) Can spatial variation alone lead to selection for dispersal? Theor Popul Biol 24(3):244–251
Howe HF (1993) Specialized and generalized dispersal systems - where does the paradigm stand. Vegetatio 108:3–13
Howe HF, Smallwood J (1982) Ecology of seed dispersal. Ann Rev Ecol Syst 13:201–228
Hubbell SP, Condit R, Foster RB (2005) Barro Colorado Forest Census Plot Data
Huntly N (1991) Herbivores and the dynamics of communities and ecosystems. Ann Rev Ecol Syst 22:477–503
Hutchinson GE (1961) The paradox of the plankton. Am Nat 95(882):137–145
Janzen DH (1970) Herbivores and the number of tree species in tropical forests. Am Nat 104 (940):501–528
Klironomos JN (2002) Feedback with soil biota contributes to plant rarity and invasiveness in communities. Nature 417(6884):67–70
Kobe RK, Vriesendorp CF (2011) Conspecific density dependence in seedlings varies with species shade tolerance in a wet tropical forest. Ecol Lett 14(5):503–510
Krishnadas M, Comita LS (2018) Influence of soil pathogens on early regeneration success of tropical trees varies between forest edge and interior. Oecologia 186(1):259–268
Lebrija-Trejos E, Reich PB, Hernȧndez A, Wright SJ (2016) Species with greater seed mass are more tolerant of conspecific neighbours: a key driver of early survival and future abundances in a tropical forest. Ecol Lett 19(9):1071–1080
Levi T, Barfield M, Barrantes S, Sullivan C, Holt RD, Terborgh J (2019) Tropical forests can maintain hyperdiversity because of enemies. Proc Natl Acad Sci 116(2):581–586
Levin SA, Muller-Landau HC, Nathan R, Chave J (2003) The ecology and evolution of seed dispersal: a theoretical perspective. Ann Rev Ecol Evol Syst 34:575–604
Levine JM, Murrell DJ (2003) The community-level consequences of seed dispersal patterns. Ann Rev Ecol Evol Syst 34(1):549–574
Loehle C (1988) Tree life history strategies: the role of defenses. Can J For Res 18(2):209–222
Mack KM, Bever JD (2014) Coexistence and relative abundance in plant communities are determined by feedbacks when the scale of feedback and dispersal is local. J Ecol 102(5):1195–1201
Mack KML, Eppinga MB, Bever JD (2019) Plant-soil feedbacks promote coexistence and resilience in multi-species communities. PLOS One 14(2):e0211572
Mangan SA, Schnitzer SA, Herre EA, Mack KML, Valencia MC, Sanchez EI, Bever JD (2010) Negative plant-soil feedback predicts tree-species relative abundance in a tropical forest. Nature 466 (7307):752–755
Miranda A, Carvalho LM, Dionisio F (2015) Lower within-community variance of negative density dependence increases forest diversity. PLOS One 10(5):e0127260
Muller-Landau HC Carson WP, Schuster S (eds) (2008) Colonization-related trade-offs in tropical forests and their role in the maintenance of plant diversity, vol 11. Wiley-Blackwell, Oxford, UK, chap
Muller-Landau HC, Adler FR (2007) How seed dispersal affects interactions with specialized natural enemies and their contribution to the maintenance of diversity. In: Dennis A J, Schupp E W, Green R J, Westcott D A (eds) Seed dispersal: theory and its application in a changing world., CABI, Oxfordshire, UK, pp 407–426
Muller-Landau HC, Wright SJ, Calderȯn O, Condit R, Hubbell SP (2008) Interspecific variation in primary seed dispersal in a tropical forest. J Ecol 96(4):653–667
Murrell DJ, Law R (2003) Heteromyopia and the spatial coexistence of similar competitors. Ecol Lett 6(1):48–59
Plotkin JB, Chave JM, Ashton PS (2002) Cluster analysis of spatial patterns in malaysian tree species. Am Nat 160(5):629–644
Sedio BE, Ostling AM (2013) How specialised must natural enemies be to facilitate coexistence among plants? Ecol Lett 16(8):995–1003
Seidler TG, Plotkin JB (2006) Seed dispersal and spatial pattern in tropical trees. PLoS Biol 4(11):e344
Snyder RE, Adler PB (2011) Coexistence and coevolution in fluctuating environments: can the storage effect evolve? Am Nat 178(4):E76–E84
Stump SM, Chesson P (2015) Distance-responsive predation is not necessary for the Janzen-Connell hypothesis. Theor Popul Biol 106:60–70
Stump SM, Comita LS (2018) Interspecific variation in conspecific negative density dependence can make species less likely to coexist. Ecol Lett 21(10):1541–1551
Stump SM, Johnson EC, Klausmeier CA (2018a) Local interactions and self-organized spatial patterns stabilize microbial cross-feeding against cheaters. J Royal Soc Interface 15(140):20170822
Stump SM, Johnson EC, Sun Z, Klausmeier CA (2018b) How spatial structure and neighbor uncertainty promote mutualists and weaken black queen effects. J Theor Biol 446:33–60
Terborgh J (2012) Enemies maintain hyperdiverse tropical forests. Am Nat 179(3):303–314
Terborgh JW (2015) Toward a trophic theory of species diversity. Proc Natl Acad Sci 112 (37):11415–11422
The MathWorks Inc (2017) MATLAB (R2017b)
The MathWorks Inc (2019) Matlab (2019a)
Tilman D (1994) Competition and biodiversity in spatially structured habitats. Ecology 75 (1):2–16
Turelli M (1978) Does environmental variability limit niche overlap? Proc Natl Acad Sci of the United States of America 75(10):5085–5089
Turnbull LA, Levine JM, Fergus AJF, Petermann JS (2010) Species diversity reduces invasion success in pathogen-regulated communities. Oikos 119(6):1040–1046
Usinowicz J (2015) Limited dispersal drives clustering and reduces coexistence by the storage effect. The Am Nat 186(5):634– 648
Visser MD, Bruijning M, Wright SJ, Muller-Landau HC, Jongejans E, Comita LS, de Kroon H (2016) Functional traits as predictors of vital rates across the life cycle of tropical trees. Funct Ecol 30(2):168–180
Wright SJ (2002) Plant diversity in tropical forests: a review of mechanisms of species coexistence. Oecologia 130(1):1–14
Yu DW, Wilson HB (2001) The competition-colonization trade-off is dead; long live the competition-colonization trade-off. The Am Nat 158(1):49–63
Zhu Y, Queenborough SA, Condit R, Hubbell SP, Ma KP, Comita LS (2018) Density-dependent survival varies with species life-history strategy in a tropical forest. Ecol Lett 21(4):506–515
Acknowledgements
This work was supported by the HPC facilities and staff of the Yale Center for Research Computing. We would like to thank an extremely helpful reviewer for their suggestions.
Funding
This research was funded by Yale University and grants NSF DEB 1457515 and NSF DEB 1845403 to Liza Comita.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A1: Deriving the formula for \({\tilde {\lambda }}_{j}^{\prime }(t)\)
A1.1 Size assumptions for analysis
Our analysis is based on Taylor Series approximations. These work well for a parameter range where the populations are approximately quadratic, though may fail if parameters are too extreme. Thus, to bound the amount of variation in our model, we define a “small” parameter 𝜖. We write O(𝜖) to indicate that a parameter is of the same order as 𝜖 (for a technical definition, see Chesson (1994)). We assume that for all species, \(Y_{j}/Y_{k} = 1 + O(\epsilon ) I_{j/_k} = 1+O(\epsilon )\), pj is O(𝜖), and \({d_{j}^{2}}(z)/{d_{k}^{2}}(z) = 1+O(\epsilon )\), and \((d_{\text {{p}}-j}\left (z\right ))^{2}/(d_{\text {{p}}-k}\left (z\right ))^{2} = 1+O(\epsilon )\) for all z. Terms that are smaller than these, such as (pj)2, are mostly left out of our approximation, leaving the growth rate of species as \({\tilde {\lambda }}_{j}^{\prime }(t)=O(\epsilon )\). We write ≈ to indicate that numbers are identical up to their O(𝜖) terms.
In a few cases in the text, we do not approximate our model as much as we could. For example, in Table 2, we mention that the impact of seedling mortality caused by a seedling’s parentS,ΔκPj, contains the term \(\left (p_{j} \widetilde {d_{j}d_{\text {{P}},j}} - \overline {p_{j}\widetilde {d_{j}d_{\text {{P}},j}}}\right ) \). We could approximate \(p_{j}\widetilde {d_{j}d_{\text {{P}},j}}\) using a Taylor series around \(p_{j}=\overline {p_{j}}\) and \(\widetilde {d_{j}d_{\text {{P}},j}}=\overline {\widetilde {d_{j}d_{\text {{P}},j}}}\) (where \(\overline {p_{j}}\) and \(\overline {\widetilde {d_{j}d_{\text {{P}},j}}}\) are the means of pj and \(\widetilde {d_{j}d_{\text {{P}},j}}\) across species) and get that
\(\overline {p_{j}}\) and \((\widetilde {d_{j}d_{\text {{P}},j}} - \overline {\widetilde {d_{j}d_{\text {{P}},j}}}) \) are both O(𝜖); therefore, the third term is O(𝜖2). Thus, we could ignore that term, and our approximation simplifies to \(p_{j} \widetilde {d_{j}d_{\text {{P}},j}} \approx p_{j} \overline {\widetilde {d_{j}d_{\text {{P}},j}}}\). However, we found that this leads to poorer approximations. Thus, there were some parts of our analysis where some O(𝜖1.5) and O(𝜖2) terms were included implicitly. We feel that the quality of our approximations (Appendix A4) justifies their inclusion and note that previous work has suggested higher order terms will at times be necessary (Chesson 1994; Barabás et al. 2018).
A1.2 Deriving \({\tilde {\lambda }}_{j}^{\prime }(t)\)
Equation 1 gives the fitness of an individual of species j. The effect of competition, C(x, t), is the number of seedlings in site x at time t. For a seed that was produced at site y to become a seedling at x, it must disperse there (which it does with probability dj(|x − y|)), and then it must survive its natural enemies. ThuS,C(x, t) can be calculated by summing this parameter over all sites and all species. Each adults of species j will disperse Yjdj(|x − y|) seeds to x, and therefore, a total of \(Y_{j} {\sum }_{y=1}^{\infty } N_{j}(y,t) d_{j}(|x-y|) \) seeds will be dispersed to x (where the summation is over all sites y). Each of those seeds will then become seedlings with probability Sj(x, t). Thus,
where \({\sum }_{j=1}^{R}\) is the summation over all species.
For the text that follows, we write the growth rate as \(\lambda _{j}^{\prime }(x,t)=(\lambda _{j}(x,t)-1)/\delta \), so that fitness is defined as 0 when there is no population growth and it is in per-generation time scale. Thus,
Note that \({\lambda }_{j}^{\prime }(x,t)\) is defined in terms of x (the position of the adult), as it will vary across space (due to the distribution of conspecific and heterospecific adults).
The summation can be seen as a weighted average,
where the covariance is over all sites y. If Sj(x, t) = Ij(1 + O(𝜖)) and Yj/Yk = 1 + O(𝜖) for all j and k (as we assumed), then \(\frac {Y_{j}S_{j}(y,t)}{C(y,t)}\approx 1+ \ln \left \{ Y_{j} \right \} + \ln \left \{ S_{j}(x,t) \right \}-\ln \left \{ C(x,t) \right \}\). Thus,
Finally, note that \({\sum }_{y=1}^{L^{2}}d_{j}(|y-x|)=1\), as it is a dispersal kernel. Thus, \( \mathbf {E}\left [{d_{j}(|y-x|)}\right ]=1/L^{2}\), and
Putting these back into Eq. 22,
This equation represents the fitness of an adult at site x. To calculate the finite rate of increase of a population, \({\tilde {\lambda }}_{j}^{\prime }(t)\), we average this over all sites containing adults of species j,
The first term represents the average fitness that an individual would have if it were placed in random location, and the second term describes the impact of spatial structure (Chesson 2000). For example, if species j is rare but highly aggregated, then \(\mathbf {E}[{{\lambda }_{j}^{\prime }(x,t)}]\) will be positive (i.e., the species is rare, so a random adult is unlikely to be in a high-mortality area), but \( \text {\textbf {cov}}\left ({\lambda }_{j}^{\prime }(y,t), N_{j}(y,t)/\mathbf {E}[{N_{j}(t)}] \right )\) will be negative (i.e., most of the individuals are aggregated in high-mortality areas). We then substitute Eq. 26 into this. The term \(\ln \left \{ Y_{j} \right \}\) and the spatial average terms are already constants, and they will not contribute to the covariance. Thus,
(where the outer covariances are over all sites x). This can be simplified further by approximating survival, Sj(x, t). By Eq. 5,
pj is O(𝜖); therefore,
The above equation is the reason that our results will hold if Sj(x, t) is an approximately linear function of conspecific density (as stated in the main text); this is why we felt justified modeling Sj(x, t) using a log-likelihood function in our simulations (described below in Appendix A3, Eq. 65). Thus,
A1.3 Invasion analysis and partitioning terms
Here, we perform an invasion analysis. We assume that species i is rare, and the other R − 1 resident species are at equilibrium in the absence of i. We assume that all species are at a long-term steady state and stable spatial distribution. Because the residents are at equilibrium, \(\tilde {\lambda }_{r}^{\prime }(t)=0\) for all r≠i. Thus,
(where the summation is over all resident species). Substituting approximations Eqs. 30 and 31 into the above equation, we can partition the invader growth rate into a series of additive terms.
We combine the terms \(\ln \left \{ Y_{j} \right \}\) and \(\ln \left \{ I_{j} \right \}\) (giving us \(\ln \left \{ Y_{j} I_{j} \right \}\)). Taking the invader-resident difference in this, we are left with ΔYi in Eq. 7. The invader-resident difference in the fourth term gives us ΔPi, Eq. 8. The invader-resident difference in the fifth term gives us ΔκPi, Eq. 10. The invader-resident difference in the sixth term gives ΔκCi, Eq. 13. The invader-resident difference in the seventh term gives \({\varDelta } {\kappa }_{\text {{P}}i}^{\prime }\), Eq. 13. Finally, the invader-resident difference in the last term gives \({\varDelta } {\kappa }_{\text {{C}}i}^{\prime }\), Eq. 14. Together, this gives us Eq. 6.
Note that Eq. 6 does not have a term comparing the \(\mathbf {E}[{\ln \left \{ C(y,t) \right \}}]\) values, as these are the same for all species, and therefore \(\mathbf {E}[{\ln \left \{ C(y,t) \right \}}] - \frac {1}{R-1}\underset {r\neq i}{\sum } \mathbf {E}[{\ln \left \{ C(y,t) \right \}}] = 0\).
Appendix A2: Simplifying the Δ terms
In this section, we simplify the Δ terms, to give the approximations in Table 2. Additionally, we break them into their stabilizing components (their average over all species), and their mean fitness-difference components (the value for a given species minus the average).
To simplify notation, we define the following:
Thus, \(\widetilde {{d}_{j}^2 }\) is the sum of dj(|x − y|)2 over all sites (i.e., the dot product of the dispersal kernel with itself), \(\widetilde {d_{j}d_{\text {{P}},j}}\) is the sum of the product of dj(|x − y|) and \(d_{\text {{p}}-j}\left (|x-y|\right )\) over all sites (i.e., the dot product of the dispersal kernel and the enemy distribution kernel), and \(\widetilde {d_{j} {d}_{\text {{P}},j}^{2}}\) is the sum of the product of dj(|x − y|) and \((d_{\text {{p}}-j}\left (|x-y|\right ))^{2}\) (i.e., the dot product of the dispersal kernel with the square of the enemy distribution kernel). These terms simplify notation below. For example, we show below that the probability that a seedling is killed by its parent’s natural enemies is related to \(\widetilde {d_{j}d_{\text {{P}},j}}\).
A2.1 Appendix: Simplifying ΔYj
We first simplify ΔYi, Eq. 7, which is the invader-resident difference in the term \(\ln \left \{ Y_{j}I_{j} \right \}\). To do this, we rewrite it such that the summation is over all species,
When we average ΔYi over all species, the \(\ln \left \{ Y_{j}I_{j} \right \} \) terms will cancel with \(\overline {\ln \left \{ Y_{j}I_{j} \right \} }\), leaving
The fitness effect for species j, \({\varDelta } Y_{j} - \overline {{\varDelta } Y}\), can thus be written with either Eq. 7 or 34.
A2.2 Simplifying ΔPj
We next simplify ΔPi, Eq. 8, which comes from differences in \( \mathbf {E}\left [{\sum \limits _{y=1}^{L^{2}}p_{j}d_{\text {{p}}-j}\left (|y-x|\right ) N_{j}(y,t) }\right ]\). The only terms that vary spatially are the Nj(y, t) terms. Thus,
\(\mathbf {E}\left [{N_{i}(t)}\right ]=0\), and dj(|y − x|) sums to 1, therefore
Because \(\underset {r\neq i}{\sum } \mathbf {E}\left [{N_{r}(t)}\right ]=1\), this term is simply \(\frac {1}{R-1}\) times the frequency-weighted mean of pr. This can rewritten as
where the covariance is over all species except species i. Thus, it tends to be smaller if the most abundant species are the least affected by their natural enemies.
Next, we calculate the stabilizing mechanism. The average of \(\frac {1}{R-1} \underset {r\neq i}{\sum } p_{r}\), when averaged over all species, is simply the mean of pr across species, \(\overline {p_{j}}\). Previous work has suggested that the average of \(\text {\textbf {cov}}^{\text {{S}}}\left (\mathbf {E}[{N_{r}(t)}], p_{r} \right )^{\{-i\}}\) can be approximated as \(\text {\textbf {cov}}^{\text {{S}}}\left (\mathbf {E}[{N_{j}(t)}], p_{j} \right )\), calculated over all species when they are at equilibrium (Stump and Comita 2018). Thus,
Additionally, previous work has suggested that the difference in the \(\text {\textbf {cov}}^{\text {{S}}}\left (\mathbf {E}[{N_{j}(t)}], p_{j} \right )\) terms will have a negligible effect on fitness-differences (Stump and Comita 2018). Thus, the fitness effect of ΔPj is
As in previous work (Stump and Comita 2018), this effect is generally minor.
A2.3 Simplifying ΔκPj
We next simplify ΔκPi, Eq. 10, which begins as
We first calculate the covariance \(\text {\textbf {cov}}\left (d_{j}(|y-x|), \ln \left \{ S_{j}(y,t) \right \} \right )\). By the law of total covariance,
where \(\text {\textbf {cov}}\left (\left . X, Y \right \vert Z\right )\) is the covariance of X and Y conditioned on some condition Z (the expectation is then over all possible Z’s). We condition our covariances on |y − x| = z (i.e., on the assumption that a seed dispersed a distance z); for notational simplicity, we write this as conditioning on z. The first term is 0, because dj(|y − x|) will be constant when z is constant. Similarly, \(\mathbf {E}\left [ \left .d_{j}(|x-y|)\right | z \right ] = d_{j}(z)\). Finally, we use our approximation in Eq. 30 to write \(\ln \left \{ S_{j}(y,t) \right \}\) as \(\ln \left \{ Y_{j} \right \}-{\sum }_{y=0}^{L^{2}}p_{j}d_{\text {{p}}-j}\left (|y-x|\right ) N_{j}(|y-x|,t)\). The term \(\ln \left \{ Y_{j} \right \}\) is constant and thus will not affect the covariance. Thus,
We next find a formula for the mean impact of natural enemies averaged over space, \(\mathbf {E}\left [ \left .{\sum }_{y=1}^{L^{2}}p_{j}d_{\text {{p}}-j}\left (|y-x|\right ) N_{j}(y,t)\right | z \right ]\). We are averaging over all possible sites x, so spatial structure does not matter (this is taken into account with \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\)). Let us define ψz as the number of sites a distance z from x. Let us first begin with the z that we are conditioning on, z = |x − y|. We know that at least one of those sites must contain a conspecific adult (i.e., the parent of the seed at x). The remaining ψz − 1 sites will contain a conspecific adult with probability E[Nj(t)]. Thus, there will on average be ψzE[Nj(t)] + 1 −E[Nj(t)] adults a distance z away (and they will reduce survival by \(p_{j}d_{\text {{p}}-j}\left (z\right )\)). At any other distance w≠|x − y|, there will be ψw sites, each will contain a conspecific adult with probability E[Nj(t)], and they will each reduce survival by \(p_{j}d_{\text {{p}}-j}\left (w\right )\). Thus,
Only the first term varies with z. Therefore,
The covariance term \(\text {\textbf {cov}}\left (d_{j}(z), d_{\text {{p}}-j}\left (z\right ) \right )\) is \(p_{j} \mathbf {E}[{d_{j}(z)d_{\text {{p}}-j}\left (z\right )}]\) − \(p_{j} \mathbf {E}[{d_{j}{z}}]\mathbf {E}[{d_{\text {{p}}-j}\left (z\right )}]\). The mean of the product is \(\frac {1}{L^{2}}\widetilde {d_{j}d_{\text {{P}},j}}\) (by our definition in Eq. 33). The mean of dj(z) and \(d_{\text {{p}}-j}\left (z\right )\) are each L2, as they are dispersal kernels and therefore must sum to 1 over all L2 sites. Thus,
If L is large, we can ignore the \(-\frac {1}{L^{2}}p_{j}\) term.
Substituting this into Eq. 10
Using a procedure similar to Eq. 34, this becomes
Thus, averaging across species, this becomes a frequency-weighted mean of \(\overline {p_{j}\widetilde {d_{j}d_{\text {{P}},j}}}\). We believe that the approximation for \(\overline {{\varDelta } P}\) will hold (i.e., that we can approximate the mean of the covariance over invaders as the covariance when all species are at equilibrium); in this case,
Additionally, if the covariances cancel out of the mean fitness differences, then
E[Ni(t)] = 0, and therefore the summation \(\underset {r\neq i}{\sum }p_{r} \widetilde {d_{r}d_{\text {{P}},r}}\mathbf {E}[{N_{r}(t)}]\) over all residents is equal to the summation \(\sum \limits _{j=1}^{R}p_{j} \widetilde {d_{j}d_{\text {{P}},j}}\mathbf {E}[{N_{j}(t)}]\) over all species. This term is \(\overline {p_{j} \widetilde {d_{j}d_{\text {{P}},j}}} \) \(+R\text {\textbf {cov}}^{\text {{S}}}\left (p_{j} \widetilde {d_{j}d_{\text {{P}},j}}, \mathbf {E}[{N_{j}(t)}] \right )\), although if we can cancel out the covariance term, then
A2.4 Simplifying ΔκCj
We next simplify ΔκCi, Eq. 13. Using the law of total covariance and conditioning on |y − x| = z (as before),
We next find a formula for \(\mathbf {E}\left [ \left .\ln \left \{ C(y,t) \right \}\right | z \right ]\). We define C(j, y, t) as the number of seedlings at y of species j; it is
Thus, \(C(y,t)=\sum \limits _{j=1}^{R} C(j,y,t)\). C(j, y, t) can be rewritten as
This will be easier to work with if its value is close to E[Nj(t)]. Thus, we next divide this divide both sides by the across-species mean of YjIj, which we call (Y I)∗. Then, we define \(\widehat {YI}_{j} = Y_{j}I_{j}/(YI)^{*} - 1\), and
We next approximate the conditional average of C(j, y, t) given an Nj(x, t) for some location x. Nj(x, t) it could be 0 or 1, we will define this later. We approximate the mean of C(j, y, t) as the value of C(j, y, t) when Nj(x, t) = E[Nj(t)]; the true mean would include an effect of the variance of Nj(x, t); however, we find that the approximations that this simplification produces fit well (see Appendix A4). Thus,
Next, we multiply these terms. The term \(\widehat {YI}_{j}\) is O(𝜖); thus, \(\widehat {YI}_{j} p_{j}\) will be small, and we will ignore it. If Nj(x, t) = 0, this becomes
If Nj(x, t) = 1,
For notational simplicity, we will define ξj(|x − y|, t) as the amount that a seed of species j would change seedling competition at y by being at x,
We can write the mean of C(y, t) using the C(j, y, t) terms
(summed over all species k). If we focus on a particular site x, then this could also be written as
i.e., the first term is the impact of all sites other than x, and the second term is the specific contribution that site x has on seedling competition at y. If we knew that species j occupied x, then
Thus, combining the above two equations,
The terms E[C(y, t)] and (Y I)∗ are within O(𝜖), and thus their ratio will be close to 1. Additionally, the ξj(|x − y|, t) terms be within O(𝜖). Thus, if we take the natural log of both sides and cancel the \(\ln \left \{ (YI)^{*} \right \}\) terms, then we are left with
Plugging (64) into our formula for the covariance, Eq. 52
(Note that the \(\ln \left \{ \mathbf {E}[{C(y,t)} \right \}]\) terms cancel, as they are constant). Therefore,
Our attempts at simplifying this equation further resulted in a poor approximation. Thus, we leave it as this. The stabilizing effect is thus the above equation averaged over species, and the fitness effect is the above equation minus the across-species average.
A2.5 Simplifying the \({\varDelta } \kappa ^{\prime }\) terms
The terms \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\) account for the effects of spatial aggregation. In order to find a simple approximation, we would need an approximation for the spatial structure of each species. We were unable to derive this from first principals. Thus, we need to study its behavior using computer simulations. Here, we outline how these terms can be calculated from simulations.
We begin with \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\). The average probability that a seed would survive can be determined by calculating the mean survival of seeds produced by each adult, and is
Thus, the per-seed average of \(\ln \left \{ S_{j}(y,t) \right \}\) can be simplified to
Thus,
The effect of Ij will cancel out of the mean log seed survival and \( \mathbf {E}[{\ln \left \{ S_{j}(y,t) \right \}}]\). Putting this into our resident-invader comparison, we find that
This result is somewhat tautological—we wanted to quantify the species-specific differences in the per-seed average log chance of seed survival, so we defined the third term as the per-seed average log chance minus the other two terms. We did this because it was mathematically correct (by definition), and because each term represents a qualitatively different effect. And, intuitively, the covariance in \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) is any impact on the per-seed mean log survival that could not be explained by the other two effects. This equation would be useless if ΔPi and ΔκPi could not be independently verified; however, as we show in the next section, we were able to run simulations where spatial aggregation was removed (i.e., so that \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) would be 0 on average). We found that, indeed, the community dynamics could be predicted fairly accurately by ΔPj, ΔκPj, ΔκCj, and ΔYj.
We can show similarly that the per-seed mean of \(\ln \left \{ C(y,t) \right \}\) (i.e., the average amount of competition experienced by a species) is
Therefore,
In Appendix A3, we run several simulations and check how \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\) vary with a species mean dispersal distance and resident-invader state.
Appendix A3: Computer simulations
In this section, we describe how we implemented our computer simulations.
To speed computation, our model worked with the Manhattan distance function (i.e., the distance between (x1, y1) and (x2, y2) is |x1 − x2| + |y1 − y2|), rather than the Euclidean distance function (i.e., the distance between (x1, y1) and (x2, y2) is \(\sqrt {(x_{1}-x_{2})^{2}+(y_{1}-y_{2})^{2}}\)). The area of a circle is different under each distance function, which affects how many trees are a given distance away. For example, imagine we placed point in a grid, with each point separated by 1 m; then, say we selected a focal point. Under the Manhattan distance function, there would be 20 points a distance 5 m away from the focal point; however, under the Euclidean distance function, there would be 28 points between 4.5 and 5.5 m away from the focal point. But, given that none of our analysis depends on the distance function used (and indeed, dA,j(z) and dj(z) are arbitrary), we do not believe that this qualitatively affected our results.
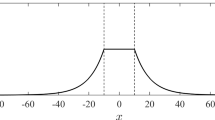
We model dispersal using a discrete approximation of a 2-dimensional t (2Dt) distribution. The probability distribution function of a 2Dt distribution with mean 0 and 2 degrees of freedom (i.e., the pdf that a seed will disperse a distance z if it is equally likely to disperse in every direction) is
where αj is a species-specific parameter. Note that the 2πz in the numerator is used because D(z) calculates the chance that it lands in anywhere a distance z away; this is generally left off to model the chance that it lands at a particular location a distance D(z) away. As stated above, Euclidean and Manhattan distances are different; thus, when we were generating seed dispersal kernels, we decided to preserve the probability that a seed would disperse a given distance, rather than the probability it would disperse to a given point.
In our simulations, we calculate dj(z) as follows: A seed that does not disperse beyond l/2 (i.e., half a site) remains in its parent’s site, and a seed that disperses between l(z − 0.5) and l(z + 0.5) is dispersed to one of the 4z sites a distance z away with equal likelihood. To reduce computational load, we assume that if a seed dispersed more than 5.5l, then it was placed in a random site (this could include sites within 5 sites, though the impact was trivial if L was large). Thus,
We modeled the community as a torus (i.e., a seed that moved off one side was warped to the other side), so that there were no edge effects.
In simulation, we modeled survival such that enemies affected tho log-odds probability of survival, rather than having a linear impact on survival. We did this so that survival would never become negative, and because this connected better with empirical literature (Comita et al. 2010). However, when pA,j and pS,j were small, the log-odds function is close enough to linear to be approximated by Eq. 2. We defined the terms \(\tilde {I}_{j}\) and \(\tilde {p}_{j}\), such that survival on the log-odds scale was
To relate these terms to our previous definitions, \(\tilde {I}_{j}\) was defined as the inverse logit of Ij (i.e., so that when there are no natural enemies, survival is Ij) and \(\tilde {p}_{j}\) was defined as \(p_{j}(1+\exp \{\tilde {I}_{j}\})\) (i.e., so that a small increase 𝜖 in the number of nearby conspecifics reduces survival by approximately pj𝜖).
We modeled the impact of distance-responsive enemies as declining exponentially according an exponential distance function (Comita et al. 2010). We calculate survival at the midpoint of a site (which was 0.25 sites for the parent’s site) and ignore adults more than 5 sites away. Thus,
where c1 is a distance constant and c2 is a constant that allows dA,j(z) to sum to 1. In all cases below, we chose c2 = 0.5 (to match empirical literature of 0.2 per m, Comita et al. (2010)), and c1 = 0.752.
A3.1 Computational details for running simulations
We modeled sites as l = 10 m squares, and usually simulated a 200 × 200 site (400 ha) community. The simulation was usually initiated by filling each site with a random individual with equal likelihood. In cases where one species’ density was held constant, we randomly filled that number of sites with the focal species and filled the remainder by randomly selecting the R − 1 other species with equal probability.
Each time step, we examined each adult to determine if it died. If it survived, then there was no change; if the adult died, then we calculated the number of seeds that were expected to fall in each site. Thus, an individual of species j at site x would contribute Yjdj(|y − x|) seeds to site y. We then calculated the impact of distance- and density-responsive enemies. If there were sj(y) seeds of species j at y, then every seed’s log-odds survival was reduced by \(s_{j}(y)\tilde {p}_{j}^{\text {{S}}}\); similarly, an adult of species j at x reduced the log-odds survival to species j seedlings at y by \({\tilde {p}}_{j}^{\text {{A}}}{d}_{j}^{\text {{A}}}(|y-x|)\). We used these to calculate Sj(y, t) and used this to calculate the expected number of seedlings at each site (it was rarely a whole number). We then chose a species randomly in proportion to the relative fraction of seedlings at the site. This procedure was repeated each time step.
In some cases, we held the frequency of one species constant. To do this, we began each time step by recording where each individual of that species was located. We then calculated the births and deaths across the community as described above. At the end of the time step, we calculated the amount that the focal population changed in order to estimate \({\tilde {\lambda }}_{j}^{\prime }(t)\), and the values needed to estimate our Δ terms. If the population had increased by n individuals, then we randomly killed n individuals of the focal population. If the population had decreased by n, then we randomly selected n individuals that had died (i.e., using the record from the start of the time step) and restored them.
We performed invasion analyses using the following steps. First, we simulated a community for 2000 time steps, to eliminate any species that was not coexisting. We also recorded the mean frequency of each remaining species. Then, each species was selected in turn to be an invader. We removed the invader and increased every other species’ density proportionately. We then simulated the community dynamics for 100 time steps, so that it could reach equilibrium and a stable spatial structure. We then introduced a small number of invader individuals (typically 50 adults). The invaders were placed in random locations, replacing the adult that was there. We ran community dynamics for several time steps (typically 13 time steps, or 5 generations), so that the invader could build up a spatial distribution, but not so long that they became common. We then continued to run the simulation for 37 time steps, and each time step, recorded data on the invader. We calculated the expected value of \({\tilde {\lambda }}_{j}^{\prime }(t)\) by calculating the probability that species j captures each site (i.e., the number of seedlings divided by the total number of seedlings, both after accounting for natural enemies), dividing that value by E[Nj(t)], multiplying that value by δ, and adding (1 − δ). We also calculated ΔYj, ΔPj, ΔκPj, ΔκCj, \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\), and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\), using approximations derived in Appendix ??. We averaged our results over 37 time steps and ran 120 replicate simulations. It was rare for an invader to die off stochastically, but when it did, we only recorded growth and the Δ values when it was alive.
A3.2 Parameter sets
The six parameter sets used for figures are listed in Table 3. In all cases, we assumed that \(\tilde {I}_{j}=-1\) for all species (i.e., Ij ≈ 0.27), that, δ = 0.4, and that \(\tilde {p}_{\text {{A}},j}=\tilde {p}_{\text {{S}},j}\). We generated parameters for 8 species, though in some cases not all persisted. The “trade-off” parameter set assumed that there was a strict trade-off between αj and \(\tilde {p}_{j}\), such that increasing \(\tilde {p}_{j}\) by 0.1 increased αj by 0.5. The “equal sensitivity” parameter set assumed that αj varied, but all species had the same \(\tilde {p}_{j}\) value; this was used to isolate the particular effects of differences in dispersal. Similarly, the “equal dispersal” parameter set assumed that \(\tilde {p}_{j}\) varied, but αj was the same between species and was used to isolate the impact of differences in natural enemy susceptibility. In the “yield differences” parameter set, species differ in only their yield values; we also assumed that \(\tilde {p}_{j}\) values were higher than in other parameter sets. We also included two “random parameters” sets, in which \(\tilde {p}_{j}\), αj, and Yj were selected randomly (without replacement) from the same distribution; these were used to test what would occur if there was not a strict trade-off.
We tested several additional parameter sets during our analysis. We included a community where species differed in \(\tilde {p}_{j}\) and had near-universal dispersal, we tested two parameter sets that lacked specialist natural enemies, and we tested an additional random parameter set. We chose not to include these data, because we felt they did not add anything. We also ran similar parameter sets but changed the range over which αj and \(\tilde {p}_{j}\) could vary, and parameters where \(\tilde {p}_{\text {{A}},j}\neq \tilde {p}^{\text {{S}}}_{j}\) (including \(\tilde {p}^{\text {{S}}}_{j}=0\)). Our results were basically similar.
Appendix A4: Checking our approximation
In this section, we describe how we used our computer simulations to check our analytical approximations. We simulated a community without spatial structure. We did this by randomly rearranging the community at the end of each time step (a method previously referred to as the “shaken” method, (Stump et al. 2018b)). This allowed us to remove the effects of spatial structure generated by clumped adult distributions (i.e., the \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\) terms), without removing the impact than adult had on its offspring (i.e., the ΔκPj and ΔκCj terms).
We studied our model in two ways. First, we performed invasion analysis on our model. We calculated the \({\varDelta } {\kappa }_{\text {{P}}i}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}i}^{\prime }\) values for each invader i, and averaged them over the 120 simulations. The approximations for \({\varDelta } {\kappa }_{\text {{P}}i}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}i}^{\prime }\) calculates the actual impact of natural enemies and competition, and then subtract out the expectation in a model without adult spatial structure. Thus, if our approximation of the non-spatial structure case is accurate, then we predict that \({\varDelta } {\kappa }_{\text {{P}}i}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}i}^{\prime }\) should be approximately 0 on average.
Second, we attempted to study our model in a non-invasion context. We could no longer assume that \({\tilde {\lambda }}_{j}^{\prime }(t)=0\) for all species; however, because the community had a fixed number of sites, \(\mathbf {E}[{N_{j}(t)}]\tilde {\lambda }_{j}\) needed to sum to 1 across all species. Thus, for all species
where the summation is over all species. We then defined the following terms:
Therefore, if spatial structure in the adult community had no effect,
To test the quality of our approximation, we simulated a shaken community with a large number of sites. We compared this to a community which was governed by the above dynamical system. All of the parameters and initial conditions were identical; thus, if our approximation perfectly represented the simulation, their dynamics would be identical to within demographic stochasticity. Additionally, at each time step, we calculated the covariance between seed density at a site x and both \(\ln \left \{ S_{j}(x,t) \right \}\) and \(\ln \left \{ C(x,t) \right \}\), along with our estimates for the covariance between those terms at dj(|y − x|), Eqs. 46 and 65.
Our approximations performed extremely well. Our approximation tended to slightly overestimate the invader growth rate of each species (Fig. 7). The measured values of \({\varDelta } {\kappa }_{\text {{P}}i}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}i}^{\prime }\) tended to be close to 0. For example, in the six communities in Fig. 7, \(\overline {{\varDelta } \kappa ^{\prime }_{\text {{P}}}}\) was measured to be between − 0.0016 and − 0.0033, and \(\overline {{\varDelta } \kappa ^{\prime }_{\text {{C}}}}\) was between − 0.0020 and − 0.0036 (i.e., indicating that there was this much error). In the non-equilibrium setting, our predictions from Eqs. 78 and 79 tended to match the simulations fairly well (Fig. 8). Additionally, during the simulations, the measured the covariance between seeds at x and both \(\ln \left \{ S_{j}(x,t) \right \}\) and \(\ln \left \{ C(x,t) \right \}\) closely matched our estimates for those terms (Fig. 8).

We ran invasion analyses on communities without spatial structure (i.e., using the shaken model) and compared its outcome to invasion analyses run using using Eqs. 78 and 79. Each dot represents the invader growth rate of a particular species. If the approximations were perfect, the dots would be on the one-to-one line. Each graph lists the parameter set used in the title

a We simulated a community without spatial structure (i.e., using the shaken model) in a large community (L = 300) and present the populations as the solid lines. We also simulated the growth of the community using Eqs. 78 and 79 and present the populations as the dotted lines (corresponding colors were the same species). We used “equal sensitivity” parameters. b At each time step of the simulation, we recorded \(\text {\textbf {cov}}\left (\text {seed density at \textit {x}}, \sum \limits _{y=1}^{L^{2}}p_{i}d_{\text {{p}}-j}\left (|y-x|\right ) N_{j}(|y-x|,t) \right )\), and also used Eq. 46 to estimate what it should be. Each dot represents an estimate at one time point for one species (different colors refer to different species). If our approximation was exact, all dots would be exactly over the one-to-one line. c This graph is similar to b, except comparing \(\text {\textbf {cov}}\left (\text {seed density at \textit {x}}, \ln \left \{ C(x,t) \right \} \right )\) to approximation (65). d through f are the same as a through c, except with the “equal dispersal” parameters. g through i are the same as a through c, except with the “random” parameters
Appendix A5: Studying our model with simulations
In this section, we describe how we used computer simulations to analyze our model.
First, simulations suggest that spatial structure made communities less stable (similar results have been shown by Bolker and Pacala (1999) and Durrett and Levin (1994)). In several of our parameter sets, fewer species persisted when there was spatial structure than when there was no spatial structure. For example, in the “equal sensitivity” parameter set, 8 species persisted without spatial structure, but only 6 persisted with spatial structure. In the “equal dispersal” parameter set, 8 species persisted without spatial structure, but only 7 persisted with spatial structure. In the “Random parameter” set, 7 species persisted without spatial structure, and 5 persisted without spatial structure. Additionally, when we ran an invasion analysis on a community with spatial structure, and then compared this to an identical community without spatial structure (i.e., a shaken model), we found that invader growth rates were lower with spatial structure (Fig. 9). In general, differences in invader growth rates can mostly be attributed to the impacts of spatial structure, \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\). For example, in the communities shown in Fig. 9, the \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\) terms explained between 67% and 98% of the difference between the simulated community and the non-spatial approximation. The remaining differences are likely caused in part by demographic stochasticity in simulations, but could also be caused by shifts in the relative abundances (which would impact \(\overline {{\varDelta } P_{j}}\)).

We ran invasion analyses on communities with spatial structure, and compared its outcome to invasion analyses run using Eqs. 78 and 79 (which does not account for spatial structure). Each dot represents the invader growth rate of a particular species. If a dot is below the line, it indicates that spatial structure reduced that species’ invader growth rates. Each graph lists the parameter set used in the title
The impact of adult aggregation on mortality risk, \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\), appeared to undermine diversity. In all of the our parameter sets, \(\overline {{\varDelta } {\kappa }_{\text {{P}}j}^{\prime }}\) was negative (i.e. it was destabilizing). It was always lower than \(\overline {{\varDelta } \kappa _{\text {{P}}j}}\), and often about twice the magnitude. \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) also produced fitness differences, which tended to be smaller in magnitude than the fitness differences produced by ΔκPj. We also found that \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) was negative for all species in nearly every simulation we ran, i.e. that even the biggest fitness advantage granted by \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) could not make up for its destabilizing effect.
The impact of adult aggregation on competition, \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\), also undermined diversity, though the impact was less strong. In all cases, \(\overline {{\varDelta } {\kappa }_{\text {{C}}j}^{\prime }}\) was negative; however, its actual effect was typically small, and usually much smaller than \(\overline {{\varDelta } \kappa _{\text {{C}}j}}\) and \(\overline {{\varDelta } {\kappa }_{\text {{P}}j}^{\prime }}\). It also tended to produce fitness effects; the fitness effects were always smaller than those of ΔκCj (the impact of the parent on competition), but could be bigger than the fitness effects of natural enemies.
We found a strong and consistent correlation between a species’ abundance and its aggregation. Measuring aggregation as \(\ln \left \{ g(3)-1 \right \}\) (i.e. the natural log of the pair correlation at 3 sites, or 30m, minus 1), we found that across our parameter sets, frequency and aggregation was approximately
for some a and b. In most cases, the slope of the line for a particular species was about − 1.2. This varied slightly but was always between − 1.1 and − 1.25 in the parameter range we tested. We are not sure why this occurred, and how much it was driven by our specific parameters. The intercept value, a differed between species. It appeared that dispersal differences had the biggest impact on a, with species with high dispersal being the least aggregated. Additionally, species with strong potential NDD had a lower a, i.e. were less aggregated, though the impact was slightly weaker than the impact of dispersal.
We found that the terms the covariance between seed density and both \(\ln \left \{ S_{j}(x,t) \right \}\) and \(\ln \left \{ C(x,t) \right \}\), the covariance which contribute to \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\), tend to increase with pair correlation function. For example, in Figs. 10 and 11 we show how they change with the pair correlation at 30m for the three different datasets. The \( \ln \left \{ S_{j}(x,t) \right \} \) covariance increases with clustering in all cases, and the \(\ln \left \{ C(x,t) \right \}\) covariance increases with clustering in all but 1 case. Both of these covariances contribute negatively to population growth, thus, the fact that they increase shows why \(\overline {{\varDelta } \kappa ^{\prime }_{\text {{P}}}}\) and \(\overline {{\varDelta } \kappa ^{\prime }_{\text {{C}}}}\) both destabilize coexistence.

We simulated community dynamics, holding one species’ abundance constant. We tracked how clustered the adult population was at each abundance, and also what \(\text {\textbf {cov}}\left (\text {seed density at \textit {x}}, \sum \limits _{y=1}^{L^{2}}p_{i}d_{\text {{p}}-i}\left (|y-x|\right ) N_{i}(|y-x|,t) \right )\) was at that abundance. Each line represents a different species

We simulated community dynamics, holding one species’ abundance constant. We tracked how clustered the adult population was at each abundance, and also what \(\text {\textbf {cov}}\left (\text {seed density at \textit {x}}, \ln \left \{ C(x,t) \right \} \right )\) was at that abundance. Each line represents a different species
The covariance terms \(\text {\textbf {cov}}\left (\text {seed density at \textit {x}}, \ln \left \{ S_{j}(x,t) \right \} \right )\) and \(\text {\textbf {cov}}\left (\text {seed density at \textit {x}}, \ln \left \{ C(x,t) \right \} \right )\) differ significantly between species, even if they are at the same clustering (Figs. 10 and 11). This shows how \(\overline {{\varDelta } \kappa ^{\prime }_{\text {{P}}}}\) and \(\overline {{\varDelta } \kappa ^{\prime }_{\text {{C}}}}\) produce fitness differences. The differences occur because the covariances are driven by other factors as well. For example, species that are more susceptible to natural enemies will have a stronger value of \(\text {\textbf {cov}}\left (\text {seed density at \textit {x}}, \ln \left \{ S_{j}(x,t) \right \} \right )\). Similarly, species with low seed dispersal will have a higher value of the covariance \(\text {\textbf {cov}}\left (\text {seed density at \textit {x}}, \ln \left \{ S_{j}(x,t) \right \} \right )\), because their seeds are more likely to stay in high-mortality areas.
Finally, we tested if trade-offs would emerge naturally due to community assembly. To do this, we randomly assembled communities of 15 species. Each species was given a potential NDD for distance-responsive enemies (pA,j) and a dispersal distance parameter (αj); these values were assigned randomly without replacement. Additionally, potential NDD for distance-responsive enemieS,pS,j, was assigned as 0.78pA,j. We calculated the correlation between pA,j and αj among the 15 species. We then simulated community dynamics for 1500 time steps, to determine which species persisted. We then calculated the correlation between pA,j and αj among species that persisted. We repeated this for 150 communities.
Community assembly tended to create a positive correlation between \(p_{j}^{\text {{A}}}\) and αj, such that species that dispersed farther were more susceptible to enemies (Fig. 12a). Our initial communities began with 0 correlation on average, though this varied with a standard deviation of 0.26. On average, 9.3 species survived in a given random community. The average correlation between pA,j and αj among survivors was 0.43 (with a standard deviation of 0.29), it was positive in 92% of simulations, and was higher than the initial community in 97% of simulations.

a We assembled communities out of 15 species. Each individual had its pA,j and αj values assigned randomly from a distribution (without replacement). We then allowed the species to compete, and determine which persisted. We calculated the correlation between pA,j and αj for all 15 species, and for those that persisted; each dot represents one such comparison. A positive correlation indicates that species that dispersed farther were more sensitive to their natural enemies (i.e. a trade-off was was occurring). pA,j values were uniformly distributed from 0.1 to 0.5. αj values were uniformly distributed from 5.5 to 7. pS,j values were set to 0.78pA,j. For other parameters, we used: Ij = 0.27, δ = 0.4, L = 120, l = 10, and Yj = 7.8. b Here we show one such randomly assembled community. Each circle represents a species that persisted, and each x represents a species that was excluded. In the initial community, the correlation between pA,j and αj was − 0.04; in the final community, the correlation was 0.39
Additionally, these results show that while a trade-off would help species coexist, a strict trade-off was not necessary, as it is for the competition-colonization trade-off and many other models of dispersal-mediated coexistence. In fact, a strict trade-off did not emerge in any of our 150 communities. Fig. 12b shows an example of this. Here, 9 of the original 15 species persisted. Among survivors, the species with the third highest dispersal has the third lowest enemy susceptibility, making that species strictly better than 5 of its 8 competitors. However, filtering still produced a correlation of 0.39; this occurred because the species that were susceptible to natural enemies could not survive unless they had reasonably high dispersal, and species that had low dispersal could not survive unless they were tolerant of their natural enemies.
Appendix A6: Measuring terms empirically
In this section, we discuss how various model parameters could be measured empirically.
A6.1 Measuring \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\)
The terms \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\) quantify how the spatial distribution of adults affects the amount of seedling mortality (due to natural enemies) and seedling competition that species experience. We believe that elements of them can be measured in an equilibrium setting. To do this, one would need to map the distribution of seedlings in many locations and estimate the impact of natural enemies at each location. This was done, for example, by Comita et al. (2010), who tracked seedling survival across 20,000 plots in Barro Colorado Island, Panama. Alternatively, one could grow seedlings in soil collected from many locations (using standard methods for plant-soil feedback studies; (Mangan et al. 2010)). First, the covariance that would produce \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }+{\varDelta } \kappa _{\text {{P}}j}\) can be quantified as the covariance between seedling density and seedling mortality. For species j, one would need to calculate the expected chance that a seedling of species j would die in each of the 20,000 plots, and calculate how this covaries with the actual number of seedlings in each plot, and then divide this by the mean number of seedlings found per plot. It is unclear what would be the best way to estimate survival in a plot without seedlings (such sites could be left out, or perhaps estimated using a regression model). Similarly, the covariance that would produce \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }+{\varDelta } \kappa _{\text {{C}}j}\) is the covariance between the number of species j seedlings in a plot and the total number of seedlings in that plot, divided by the mean number of species j seedlings in a plot.
The above method has a few drawbacks. First, both of these effects calculate the total impact of spatial structure (i.e. including the impact of the seedling’s parent); this is probably preferable, though if the impact of the parent needs to be removed, one could subtract what we expect ΔκPj and ΔκCj to be (based on our model). Second, the method for calculating \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }+{\varDelta } \kappa _{\text {{P}}j}\) technically measures the spatial structure of seedling survival, rather enemies specifically. It could potentially be flawed if habitat partitioning is occurring, and species are clustered in areas where they have high density-independent survival (Stump and Chesson 2015). Similarly, the method for calculating \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }+{\varDelta } \kappa _{\text {{C}}j}\) is based on the assumption that inter- and intraspecific competition are similar (i.e. that crowding matters, but not which species are causing the crowding); our method will give an inaccurate picture if this assumption is far from true. Last, both measure the covariances in an equilibrium condition, whereas \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }+{\varDelta } \kappa _{\text {{P}}j}\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }+{\varDelta } \kappa _{\text {{C}}j}\) are for invasion situations. This could still be useful, as it would likely indicate the scope of fitness differences. It could also be used to test some of our models predictions, such as that the covariances contributing to \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }+{\varDelta } \kappa _{\text {{P}}j}\) and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }+{\varDelta } \kappa _{\text {{C}}j}\) will be higher for species with low seed dispersal, and for rarer species.
A6.2 Measuring how limited seed dispersal reduces the stabilizing mechanism
In this section, we derive (19) of the main text, which shows how limited seed dispersal reduces the stabilizing effect of natural enemies. We then give an example of how one could measure this, using parameter estimates from Muller-Landau et al. (2008).
The basic principal of Eq. 19 is that we calculate what the stabilizing effect from \(\overline {{\varDelta } P_{j}}\) and \(\overline {{\varDelta } \kappa _{\text {{P}}j}}\) are, and divided this by what it would be if seeds had 100% dispersal (i.e. \(\overline {{\varDelta } P_{j}}\) alone). The term \(\overline {{\varDelta } P_{j}}\) is the mean of pjE[Nj(t)], and \(\overline {{\varDelta } \kappa _{\text {{P}}j}}\) is the mean of \(-p_{j}\widetilde {d_{j}d_{\text {{P}},j}}\mathbf {E}[{N_{j}(t)}]\). Thus,
\(\widetilde {d_{j}d_{\text {{P}},j}}\) is the chance a seed encounters its parent’s natural enemies, and the second term is the mean of that term across species. Of course, this effect is not the same for all species, and the third term accounts for this variation. That third term is not the same as \(\frac {1}{R-1}\text {\textbf {cov}}\left ({p_{j}}, {\widetilde {d_{j}d_{\text {{P}},j}}} \right ) + \overline {p_{j}}\text {\textbf {cov}}\left ({\mathbf {E}[{N_{j}(t)}]}, {\widetilde {d_{j}d_{\text {{P}},j}}} \right )\), though it is a good enough approximation for intuition. First, if there is a dispersal-sensitivity trade-off, then the species with the highest pj (those most susceptible to natural enemies) will have the lowest \(\widetilde {d_{j}d_{\text {{P}},j}}\) (i.e. most seeds will escape their parents natural enemies); in this case, the covariance will be negative, and thus the stabilizing mechanism will be strengthened. However, if the species that are the most common have the highest dispersal (which we might expect given the fitness advantage), then this will contribute positively to the covariance, and therefore reduce the stabilizing mechanism.
The third term requires significantly more information to assess. As such, simply quantifying \(\overline {\widetilde {d_{j}d_{\text {{P}},j}}}\) will give a first rough estimate, as it will show how much limited seed dispersal weakens the mechanism in the absence of a dispersal-sensitivity trade-off. If a dispersal-sensitivity trade-off is occurring, then \(\overline {\widetilde {d_{j}d_{\text {{P}},j}}}\) is an upper-bound of how harmful limited seed dispersal is.
To give an example of how this can be done, we used data from Muller-Landau et al. (2008). They estimated dispersal kernels for 41 species on Barro Colorado Island, Panama. For our work, we focused on the 26 canopy tree species they used (“canopy species” defined in (Comita et al. 2007)). Those values are in Table 4. In a few cases, Muller-Landau et al. (2008) calculated two estimates for α (the dispersal distance parameter in a 2Dt distribution); in these cases, we used data that was fit to seed-fall data rather than fruit.
Our model predicts that the dispersal kernel of density-responsive enemies is equal to the seed dispersal kernel. Thus, for density-responsive enemies, \(\widetilde {d_{j}d_{\text {{P}},j}}\) is \(\widetilde {d_{j}^2}\). So, we first calculated dj(z) for each species, for a distance between 0 and 8 (we still assumed that trees would take up approximately a 10×10m area). Instead of using Eq. 75, which relied on Manhattan distances, we used the following formula:
(with D(y) in Eq. 74). For example, Anacardium excelsum has a dispersal parameter αj = 4.9. Thus,
Next, we squared each term. Finally, we multiplied dj(z)2 by the area between 10(z − 0.5) and 10(z + 0.5) (i.e., 0.79, 6.28, 12.57, 18.85, 25.13, 31.42, 37.70, 43.98, and 50.27m2), and summed those values. Thus, for A. excelsum, it is 0.07.
We found that across canopy trees, \(\widetilde {d_{j}d_{\text {{P}},j}}\) varies from 0.002 (Zanthoxylum ekmanii) to 0.193 (Beilschmiedia pendula), with a mean of \(\overline {\widetilde {d_{j}d_{\text {{P}},j}}} = 0.057\). This suggests that in the absence of a dispersal-sensitivity trade-off, limited seed dispersal weakens the stabilizing effect of density-responsive enemies by about 6%. Future studies could improve this estimate by quantifying how pj covaries with \(\widetilde {d_{j}d_{\text {{P}},j}}\), and whether more common species have higher \(\widetilde {d_{j}d_{\text {{P}},j}}\).
A6.3 Measuring dispersal-susceptibility trade-offs
In this subsection, we discuss how our model could be used to test for dispersal-susceptibility trade-offs.
At a basic level, a dispersal-susceptibility trade-off indicates that species that disperse their seeds farther are more susceptible to natural enemies. This could be done, by calculating each species’ mean dispersal distance, or some similar parameter (e.g. α in a 2Dt distribution, Muller-Landau et al. (2008)), and correlating this with their potential CNDD (measured using techniques discussed in the main text). If the correlation is positive (i.e. species with higher dispersal are more susceptible), it indicates a trade-off is occurring. Indeed, this is essentially what we did in our simulations in Fig. 12. We are not currently aware of anyone who has done this.
Ideally, one would show that this trade-off is equalizing. This is somewhat complicated, as there is no good definition of “equalizing” in a multispecies community (Barabás et al. 2018). A mechanism is called equalizing if it reduces mean fitness-differences between species. In a two-species community, this is simple to calculate, as sp. 1’s fitness is equal to negative sp. 2’s fitness; thus, if a trade-off causes the absolute value of both decrease, it is equalizing. In a community with three or more species, however, this result is more complex.
With that caveat aside, we would suggest that the best way to see if this trade-off is equalizing is to check whether the trade-off affects the variance in mean fitness differences. The term ΔPj will not contribute much to fitness-differenceS,ΔκCj requires a huge number of parameters (and we worry the quantitative values in Eq. 71 may be model-specific), and \({\varDelta } {\kappa }_{\text {{C}}j}^{\prime }\) and \({\varDelta } {\kappa }_{\text {{P}}j}^{\prime }\) cannot be calculated reliably from parameters alone; therefore, we suggest focusing on ΔκPj. To do this, one would calculate \(p_{j} \widetilde {d_{j}d_{\text {{P}},j}}\) for each species, using methods described above, and determine its variance. Then, one would calculate what the variance of \(p_{j} \widetilde {d_{j}d_{\text {{P}},j}}\) is if all species had identical \(\widetilde {d_{j}d_{\text {{P}},j}}\). We would recommend setting \(\widetilde {d_{j}d_{\text {{P}},j}}\) to what \(\widetilde {d_{j}d_{\text {{P}},j}}\) would be if every species had the same mean seed dispersal, although an argument could be made for setting \(\widetilde {d_{j}d_{\text {{P}},j}}\) to the community-average value of \(\widetilde {d_{j}d_{\text {{P}},j}}\). In either case, if the variance is higher when species have identical \(\widetilde {d_{j}d_{\text {{P}},j}}\) values, then the trade-off is equalizing; otherwise it increases fitness differences.
Rights and permissions
About this article

Cite this article
Stump, S.M., Comita, L.S. Differences among species in seed dispersal and conspecific neighbor effects can interact to influence coexistence. Theor Ecol 13, 551–581 (2020). https://doi.org/10.1007/s12080-020-00468-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12080-020-00468-5